Efficient Support for Unique Names in Capabilities
Capability based protection schemes require that the identifiers for objects which appear in capabilities are unique. In most capability systems developed in the 1970s this meant that a central object table was required via which the unique names in capabilities could be translated into addresses. Such a central table has several disadvantages, because it dynamically changes rapidly, it contains entries for different kinds (and granularities) of objects, it is usually too large to fit into the main memory, etc. Some of these disadvantages have been described in:
Keedy, J.L. "An Implementation of Capabilities without a Central Mapping Table", Proc. 17th Hawaii International Conference on System Sciences, 1984, pp.180-185.
In the Monads systems these disadvantages were eliminated by using large unique virtual addresses as object identifiers in capabilities. To achieve this a two level capability scheme was developed. At the memory addressing level segment capabilities were introduced. A segment capability basically has the same structure as a segment table entry in the orthogonol paging and segmentation model, as is illustrated below.
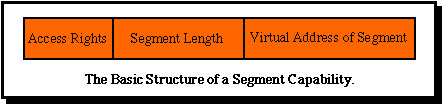
The start address of the segment is a full unique virtual address (in the Monads-PC a 60 bit persistent virtual address), which can directly address any segment in the virtual memory. The length field in the Monads-PC segment capability allows a segment to be up to 228 bytes long and the access rights define how the segment can be accessed. The machine architecture of the Monads II and Monads-PC systems supports a set of capability registers, into which segment capabilities can be loaded by special instructions. (Earlier systems such as the Plessey System 250 had capability registers containing main memory addresses, not virtual addresses.) Addressing modes in programs thus have variants of the form «cap.reg.#, offset», so that the long unique virtual addresses do not adversely influence program size or efficient addressing.
The persistent virtual memory is decomposed into "address spaces", each of which is allocated a 28 bit addressing range, so that a large persistent virtual address can be viewed as a two part entity: «address space #, offset in address space», as shown.
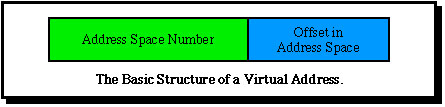
An address space is roughly equivalent to a file (but also to a process stack) in a conventional system. All the logical segments in a data file or a program file are held in a single address space. This has several advantages.
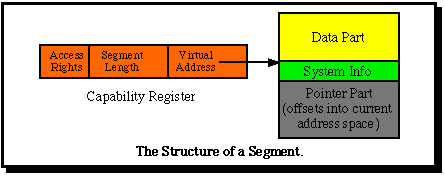
First, the «offset in address space» part of a virtual address is sufficient uniquely to identify the start address of a segment in an address space for which the «address space #» part is known. Thus pointers between the segments of a particular data or program file can be framed in terms of offsets, which are 28 bits wide. However, such pointers must be protected if they are used as capability lists, i.e. for loading addresses into capability registers. To achieve this a segment is partitioned along the same lines as in Hydra into a data part and a pointer part (and a part with some additional system information). Access to pointers is only possible using special instructions. Thus pointers are as efficient as in conventional systems, despite the large size of full virtual addresses.
Second, the «address space #» part of a virtual address uniquely identifies a file (or a process). This allows the introduction of a second kind of capability, a module capability, which identifies a file (or a process) in the virtual memory and contains a set of access rights. Since all Monads modules (including files) are uniformly implemented as information hiding modules the access rights can be framed in terms of the entry points of the file or program which may be invoked by the possessor of the module capability.
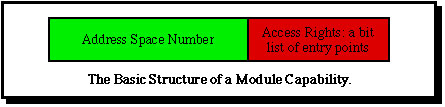
Module capabilities not only have an entirely different structure from segment capabilities but also an entirely different function, which means that they can be managed and optimized differently. A module capability is required by a process in order to invoke an entry point of a module. Once in the module the process is provided with an appropriate addressing environment in terms of segment capabilities. (The segment capabilities associated with the previous environment are invalidated, except those passed as parameters.) Module capabilities themselves are stored in the data part of user segments and like all other segments are addressed by capability registers. To protect module capabilities from unauthorized modification the segments holding them are marked as special, and can only be accessed by special instructions.
From the system viewpoint module capabilities are very efficient, because the unique identifier of a module is at the same time a virtual address space number, which means that literal offset values can be concatenated to it to form a full virtual address, which can then be used in the normal way. For example by concatenating 28 zero bits to the identifier the system has, and can directly use, the address of the first byte of an address space. Since the orthogonal paging and segmentation scheme, together with segment capability protection, allows an address space to hold system segments which cannot be addressed by normal users (including the owner of the file), the first page of a file can include useful system information (including the initial segment capability list, the page table for mapping page numbers to disk addresses, etc.). Because it can place such information in fixed positions of a newly created address space, the kernel can thus efficiently address them by concatenating appropriate literal values to the address space number taken from a module capability.
This leads to a further efficiency gain. The system and user information associated with a file can be placed alongside each other in a single page and are therefore brought into the main memory together using normal paging. In fact the entire information of a small file can often be found in a single page, which results in a very efficient paging mechanism both in terms of runtime access to information and in terms of space management.
From the user viewpoint module capabilities have an entirely different advantage. Because they can be stored in user segments of user files the user can organize his module capabilities as he chooses. In effect this means that he can develop his own directory system, as is described under the heading "User Directory Systems".
One final effect of this organization of capabilities is that the operating system becomes much simpler and has a lesser status than in other systems. Even the directory software is not an essential part of an operating system! In practice type managers for directory software is of course provided as a default for the user in the Monads systems. And, as was already indicated, there is no central object table.