Distributed Shared Virtual Memory
The first paper worldwide to propose the idea of distributed shared virtual memory was published by Prof. Keedy and his former research student David Abramson in early 1985:
Abramson, D.A. and Keedy, J.L. "Implementing a Large Virtual Memory in a Distributed Computing System", Proceedings of the 18th Hawaii International Conference on System Sciences, 1985, pp.515-522.
This was a natural extension of the idea of a uniform persistent virtual memory, which they had already developed in association with John Rosenberg and which had already been implemented in the Monads II and Monads-PC systems.
The basic idea is simply that communication between the nodes of a (local area) network of computers takes place implicitly via a shared virtual memory. In this shared memory all virtual addresses are unique. The actual pages can be stored on disks which can be loaded on any of the computers in the network. When a process uses virtual addresses it is not explicitly aware of the location of the disk. If a page fault occurs, it is the task of the kernel's virtual memory manager to locate the corresponding page in the network and arrange for its transfer into the main memory of the node at which the page fault occurred. Thus processes communicate with each other implicitly via virtual memory objects (files) rather than explicitly in the network. The normal unit of information transfer in the network is therefore a page.
This organization raises some interesting issues. First, how can it be arranged that addresses throughout the network are unique? The Monads solution was based on very large virtual addresses. In the local persistent virtual memory a virtual address was decomposed as follows:
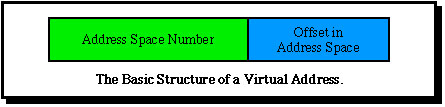
In practice this was already viewed by the software as a three part address, in order to allow the page fault software rapidly to determine on whch disk the address space was located, as follows:
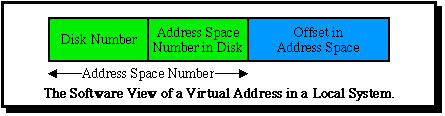
As a further natural extension of this scheme the software view of an address space number was further decomposed to include a field to indicate a processor numbers, as follows:

With this virtual address structure the page fault software can take the virtual address which causes a page fault and (in the best case) determine directly from the processor number part at which node the required page is stored, then this node can determine from the disk number on which of its disks the page is located, with the address space number in disk allowing the appropriate "file" on the disk to be located.
This best case assumes that a disk is always loaded at the processor which initialized it, and that the file is on the disk where it was initially created. These conditions do not always hold, of course. Solutions for such cases are discussed in:
Keedy, J.L., Brössler, P., Henskens, F.A. and Rosenberg, J. "Addressing Objects in a Very Large Distributed System", Proceedings of the IFIP Conference on Distributed Systems, Amsterdam, 1987.
Virtual addresses organized in this way are potentially rather long, especially if they are to be unique as in the Monads systems in the sense that any address for any disk created by a Monads processor can be loaded onto any other Monads system, since it implies that processor numbers must not only be unique in a local area network but worldwide. For this purpose even the 60 bit addresses of the Monads-PC proved to be too short and for the Monads-MM systems it was planned to have 128 bit virtual addresses. (This problem is solved in a different way in the later S-RISC project.)
There are some other interesting problems, e.g. maintaining consistency/coherence for the pages of virtual memory which are concurrently needed at more than one node in a network. As was pointed out in the initial paper, this is similar to the cache coherence problem. There a form of the "write invlaidate" technique was described for use in Monads.
Another problem is maintaining the stability of a distributed shared virtual memory. The Monads approach to this is described in:
Henskens, F.A., Rosenberg, J. and Hannaford, M.R. "Stability in a Network of Monads-PC Computers", in Proc. International Workshop on Computer Architectures to Support Security and Persistence of Information, Springer-Verlag, pp. 246-258, 1990.
Some of the advantages of the Monads approach to distributed shared memory are as follows:
- Software above the level of the virtual memory can be developed without consideration for issues concerned with distribution. This is discussed in more detail in:
Keedy, J. L. "Is Distribution a Genuine Problem for Persistent Systems or is Addressing the Real Problem?", Proceedings of the 28th Hawaii International Conference on System Sciences, 1995, pp.695-704.
- A network configuration can easily be changed without affecting users (e.g. disks can be distributed across the nodes of a network or concentrated at specific server nodes)
- Capabilities can be transferred across the network as part of the normal paging operations. They are protected by the normal virtual memory protection mechanisms
For a much more detailed discussion of the Monads distributed shared virtual memory, see:
Henskens, F. "A Capability-Based Persistent Distributed Shared Virtual Memory", Ph.D. Thesis, University of Newcastle, N.S.W., 1991.